How llm-d Prefix-Cache Routing Made Qwen 7B on EKS 2.3x Faster
Date: 26 June 2026

Introduction
I wanted to benchmark how much the routing layer matters for LLM inference when the workload has repeated long prefixes.
The setup was intentionally simple: Qwen2.5-7B-Instruct, vLLM, AWS EKS, FSx for Lustre, and eight g5.xlarge GPU nodes. Each node had one NVIDIA A10G GPU and ran one vLLM decode replica. The interesting part was the comparison in front of those same eight pods.
One path used a plain Kubernetes ClusterIP Service, which effectively gives round-robin-style traffic distribution. The other path used llm-d with the precise prefix-cache-aware endpoint picker.
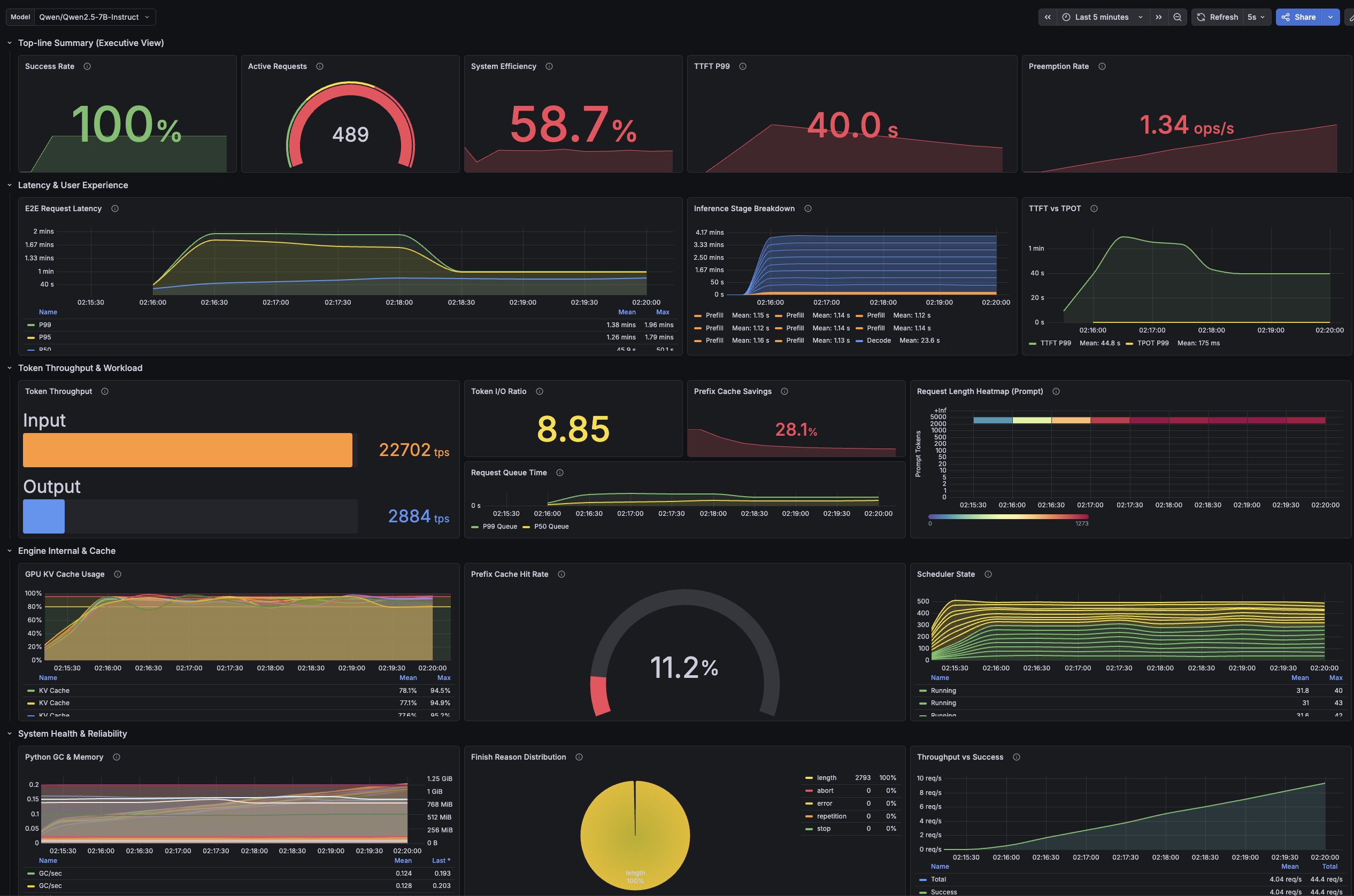
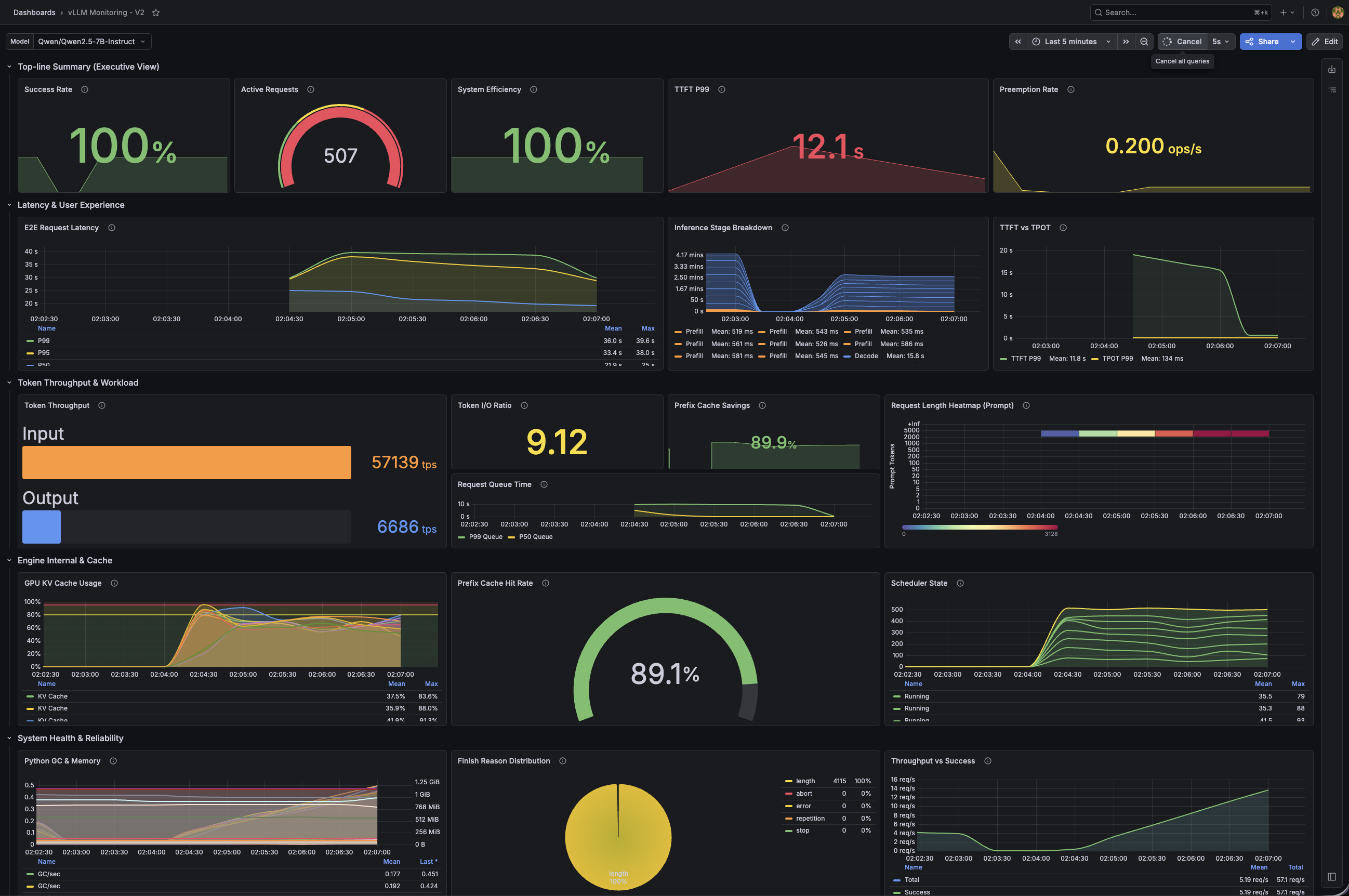
The result was not small. With the same hardware and the same vLLM pods, llm-d finished the 512-concurrency benchmark in 358.7 seconds instead of 840.2 seconds. Output throughput went from 2,742 tok/s to 6,423 tok/s, and mean time to first token dropped from 19.0 seconds to 0.86 seconds.
The Problem
vLLM has a KV cache. If many requests share the same long prefix, the best case is to reuse the cached prefix blocks instead of recomputing the prefill again and again.
But there is a catch: each vLLM replica has its own KV cache.
With plain round-robin routing, repeated-prefix requests are scattered across replicas. A request may land on a pod that has never seen that prefix before, even though another pod already has the right KV blocks. That means the cluster burns GPU time on repeated prefill work, fills KV cache, and eventually starts queueing requests.
llm-d solves this specific problem by making routing aware of prefix-cache locality. In this benchmark, the llm-d endpoint picker routed prompts to the replica that was most likely to already hold the matching prefix blocks.
Architecture

The benchmark cluster was built on AWS EKS in us-west-2.
The main components were:
- 8 x
g5.xlargeGPU nodes, each with 1 x NVIDIA A10G 24 GB. - 1 x
m6i.4xlargesystem node for support workloads. - 8 vLLM decode pods, one per GPU node.
- Qwen2.5-7B-Instruct weights mounted from FSx for Lustre.
- NVIDIA GPU Operator for device plugin, DCGM exporter, validators, and GPU discovery.
- kube-prometheus-stack for Prometheus and Grafana.
- llm-d EPP router with precise prefix-cache routing.
- A baseline Kubernetes Service named
vllm-roundrobinthat selected the same decode pods.
The important detail is that both paths used the same eight vLLM decode pods. The only meaningful difference in the A/B test was the routing layer.

Realization
The infrastructure was created with Terraform, then the cluster dependencies were installed with Helm and scripts:
./scripts/tf-init.sh
./scripts/tf-apply.sh
./scripts/update-kubeconfig.sh
./scripts/install-gpu-operator.sh
./scripts/install-fsx-csi-driver.sh
./scripts/install-monitoring.sh
The model weights were not downloaded by the inference pod at runtime. They were already available on FSx for Lustre and mounted into the pods. This made pod restarts much faster and avoided pushing large model downloads into the benchmark path.
For the llm-d test, I installed the precise prefix-cache routing stack and used the repo customization under deploy/llm-d/. The important pieces were:
patch-vllm.yaml: configured 1 GPU per replica, local FSx Qwen path, GPU scheduling, KV events over ZMQ, and--block-size=64.router.values.yaml: configured the EPP router and precise prefix-cache scorer.fsx-pvc.yaml: added a static FSx PV/PVC for the llm-d namespace.baseline-rr-service.yaml: created the plain Kubernetes Service for the round-robin baseline.
There were also a few practical gotchas:
- The baseline vLLM deployment had to be scaled to zero while running the llm-d demo, otherwise it occupied one GPU and the eighth decode pod could not schedule.
- The llm-d EPP pod needed a larger system node because its containers request enough CPU and memory that a tiny system node is not enough.
enableServiceLinks: falsewas important for vLLM pods, because Kubernetes service environment variables can collide with vLLM's ownVLLM_PORT.- The vLLM
--block-sizeand the router scorer block size had to match.
Benchmark Setup
The main benchmark used vllm bench serve with a repeated-prefix dataset:
dataset: prefix_repetition
prefixes: 150
prefix length: 2048 tokens
suffix length: 128 tokens
output length: 256 tokens
request rate: inf
max concurrency: 512
prompts: 9000
The benchmark was collected on 15 June 2026.
I also ran a smaller rate ladder at requested rates of 20, 40, and 60 requests per second. That helped show where the round-robin path started saturating and where llm-d still had useful headroom.
Results
Here is the 512-concurrency result:
| Metric | Round-robin | llm-d | llm-d advantage |
|---|---|---|---|
| Successful / failed requests | 9000 / 0 | 9000 / 0 | Same |
| Benchmark duration | 840.2 s | 358.7 s | 2.3x faster |
| Request throughput | 10.71 req/s | 25.09 req/s | +134% |
| Output token throughput | 2,742 tok/s | 6,423 tok/s | +134% |
| Total token throughput | 26,362 tok/s | 61,748 tok/s | +134% |
| Mean TTFT | 19,029 ms | 863 ms | -95% |
| Median TTFT | 18,458 ms | 340 ms | -98% |
| P99 TTFT | 36,739 ms | 12,544 ms | -66% |
| Mean TPOT | 109.2 ms | 75.3 ms | -31% |
| P99 TPOT | 157.4 ms | 111.0 ms | -29% |
| Prefix cache hit rate | about 11% | about 93% | Much higher |
| GPU KV cache usage | about 98-99% | about 64-71% | Avoided saturation |
| Waiting requests | about 180 | 0 | Queue removed |
The rate ladder showed the same shape:
| Requested rate | Endpoint | Achieved req/s | Output tok/s | Mean TTFT | P99 TTFT | Mean TPOT |
|---|---|---|---|---|---|---|
| 20 req/s | Round-robin | 7.05 | 1,805.9 | 3,338.5 ms | 17,075.5 ms | 78.5 ms |
| 20 req/s | llm-d | 11.85 | 3,034.4 | 514.0 ms | 1,142.9 ms | 52.8 ms |
| 40 req/s | Round-robin | 8.57 | 2,192.7 | 22,055.0 ms | 56,710.0 ms | 99.9 ms |
| 40 req/s | llm-d | 22.64 | 5,795.0 | 1,901.0 ms | 5,585.9 ms | 76.5 ms |
| 60 req/s | Round-robin | 8.90 | 2,278.1 | 41,661.2 ms | 90,767.7 ms | 104.3 ms |
| 60 req/s | llm-d | 21.52 | 5,507.9 | 3,496.8 ms | 8,605.3 ms | 122.3 ms |
Round-robin saturated very early. Even when I requested 40 or 60 req/s, it only delivered about 8 to 9 req/s. TTFT then collapsed into tens of seconds.
llm-d did not make the GPUs infinitely fast, of course. Eight A10Gs still have a real ceiling. But it moved the useful ceiling much higher because it avoided a large amount of repeated prefill work.
Why llm-d Won
The workload had 150 repeated long prefixes. That is exactly the kind of traffic where cache locality matters.
Round-robin distributed requests without knowing which replica had which prefix in its KV cache. So requests kept forcing prefills on replicas that did not need to do that work if traffic had been routed differently.
With llm-d, vLLM emitted KV events and the router used those events to build a prefix-cache-aware view of the replicas. When the next request arrived, the endpoint picker could prefer the replica that already had the relevant prefix blocks.
The result:
- Prefix cache hit rate increased from about 11% to about 93%.
- Waiting requests dropped from about 180 to zero.
- KV cache stayed around 64-71% instead of pinning near 99%.
- Output throughput more than doubled.
- Mean TTFT dropped by about 95%.
The most interesting part is that this was not a model change, GPU change, or replica-count change. It was the routing layer.
Notes From The Run
The vLLM logs showed the llm-d path running with no waiting queue while the prefix hit rate warmed up:
Running: 64 reqs, Waiting: 0 reqs, GPU KV cache usage: 62.1%, Prefix cache hit rate: 63.5%
Running: 68 reqs, Waiting: 0 reqs, GPU KV cache usage: 68.9%, Prefix cache hit rate: 66.4%
Running: 76 reqs, Waiting: 0 reqs, GPU KV cache usage: 70.1%, Prefix cache hit rate: 72.7%
The final aggregate showed a wider P99 TTFT than the steady-state Grafana view, because the beginning of the run included cold-cache ramp-up. After the cache warmed, the median TTFT was 340 ms and the steady-state dashboard showed the system serving 512-concurrency traffic without queue buildup.
There was also an FSx CSI controller warning about missing DescribeFileSystems permission. In this setup it was not blocking, because I used static FSx PV/PVC configuration. The file system identity and mount details were already known, so dynamic FSx discovery was not part of the benchmark path.
Conclusion
This benchmark was a good reminder that LLM inference performance is not only about the GPU count.
For repeated-prefix workloads, the routing layer can decide whether the cluster reuses KV cache or recomputes the same long prefixes again and again. In this run, llm-d precise prefix-cache routing made the same 8 x A10G fleet finish the workload 2.3x faster, while cutting mean TTFT by 95%.
If your traffic has shared system prompts, long common instructions, retrieval templates, chat prefixes, or agent scaffolding, round-robin routing can quietly waste a lot of GPU time. Prefix-cache-aware routing is one of those changes that looks small in the architecture diagram but very large in the benchmark results.
I hope you enjoyed this article.
You can find all of my code in my GitHub repository: https://github.com/andygolubev/aws-eks-inference-llmd-vllm-benchmark-qwen-7b
Feel free to connect with me on LinkedIn: https://www.linkedin.com/in/andy-golubev/